
Stellen Sie sich vor, Sie kaufen ein Bio-Produkt, nur um festzustellen, dass das Saatgut gentechnisch verändert und der Boden mit unbekannten Substanzen belastet war.
Ähnlich verhält es sich gerade mit vielen als «offen» deklarierten KI-Modellen. «Open-Source-KI» verspricht Unternehmen, Entwickler*innen und Visionär*innen mehr Kontrolle, um der Abhängigkeit von grossen Tech-Giganten zu entkommen. Doch hinter diesem Versprechen verbergen sich Fallstricke: unklare Lizenzen, intransparente Trainingsdaten, die unkalkulierbare Risiken wie «Memorisation» bergen, sowie sogar geopolitische Interessen, die bis in den Kern der Modelle eingewoben sind.
In diesem Blogbeitrag erklären wir, was «echtes Open Source» wirklich bedeutet, werfen einen kritischen Blick auf die prominentesten KI-Modelle aus den USA, China und Europa und zeigen auf, warum der blosse Betrieb auf einem Schweizer Server eine trügerische Sicherheit sein kann.
Was ist Open-Source-KI?
Open-Source-KI bezeichnet künstliche Intelligenz, deren entscheidende Kernkomponenten öffentlich zugänglich, einsehbar, veränderbar und frei weiterverwendbar sind. Diese drei Bausteine sind:
- Der Quellcode, also die eigentliche Architektur des Modells.
- Die Trainingsdaten, die dem Modell beigebracht haben, was es weiss.
- Die Modellgewichte, die das «Gehirn» des Modells bilden und seine Fähigkeiten definieren.
Genau hier liegt der Unterschied zwischen Modellen mit nur offenen Gewichten (Open-Weight) und wirklich quelloffenen Modellen (True Open-Source). Während Open-Weight oft nur die finalen Modellgewichte freigibt, legt True Open-Source alle drei Komponenten offen. Nur so wird eine vollständige Analyse, Anpassung und Reproduktion des Trainings möglich.
Dieses Konzept der vollständigen Transparenz, also True Open-Source, bricht die «Black Box» vieler kommerzieller KI-Systeme auf und basiert, laut der offiziellen Definition der Open Source Initiative, auf vier zentralen Freiheiten:
- Nutzung (Use): Die Freiheit, das KI-System für jeden beliebigen Zweck zu nutzen.
- Untersuchung (Study): Die Freiheit, genau zu untersuchen, wie das System funktioniert, was den Zugang zu allen Komponenten voraussetzt.
- Modifikation (Modify): Die Freiheit, das System für eigene Zwecke zu verändern und anzupassen.
- Teilen (Share): Die Freiheit, das ursprüngliche oder das modifizierte System mit anderen zu teilen, um die kollektive Entwicklung voranzutreiben.
Nicht alles, was glänzt, ist Open Source
Die Bezeichnung «offen» ist im globalen Wettlauf um die KI-Vorherrschaft zu einem Marketinginstrument geworden. Doch hinter der Fassade verbergen sich oft erhebliche Unterschiede. Ob ein Modell wirklich vertrauenswürdig ist, hängt nicht nur von seiner Leistung, sondern vor allem von seiner Transparenz, seiner Lizenz sowie dem rechtlichen Rahmen, in dem es operiert, ab. Die Unterschiede werden deutlich, wenn man sich die einzelnen, weltweit agierenden Akteure ansieht.
KI-Modelle aus den USA
Llama: Die Llama-Modelle von Meta AI gelten als die vielleicht stärksten Konkurrenten zu den grossen geschlossenen Systemen. Meta verfolgt eine «Open Weight»-Strategie, bei der die Modellgewichte breit verfügbar gemacht werden. Obwohl die Modelle nicht im strengen Sinne Open Source sind, treibt ihre Verfügbarkeit die Innovation voran und unterstützt Meta bei der Integration von KI in eigene Produkte. Jedoch wird die Nutzung von Llama gerade in der EU/CH kritisch gesehen. Der Hauptgrund dafür ist die mangelnde Transparenz bezüglich der Trainingsdaten. Dies kann zu Memorisation führen. Das bedeutet, dass ein KI-Modell in der Lage ist, bestimmte Phrasen oder Passagen aus seinen Trainingsdaten wortwörtlich wiederzugeben. Dies ist insbesondere bei sensiblen oder privaten Informationen problematisch.
gpt-oss: Im August 2025 hat OpenAI mit gpt-oss zwei hochmoderne Open-Weight-Sprachmodelle veröffentlicht. Aufgrund der offenen Lizenzierung und freien Nutzung ist das Modell für Entwickler*innen und Forscher*innen deutlich zugänglicher als frühere OpenAI-Modelle. Wie bei den Llama-Modellen ist es jedoch nicht vollständig transparent im Sinne von Open Source.
KI-Modelle aus China
DeepSeek R1: Obwohl dieses KI-Modell aus China durch beeindruckende Effizienz und niedrige Betriebskosten besticht, ist gerade seine Herkunft die Quelle wesentlicher Bedenken. Das chinesische Rechtssystem schafft hier einen direkten Interessenkonflikt. Nach chinesischem Recht haben chinesische Behörden umfangreichen Zugriff auf gespeicherte Daten. Dies gilt auch dann, wenn die Daten auf Servern ausserhalb Chinas liegen, solange es um personenbezogene Daten chinesischer Bürger*innen geht oder die Datenverarbeitung mit dem Angebot von Produkten und Dienstleistungen an Personen in China verbunden ist. Das widerspricht dem deutlich höheren Schutzniveau, das Nutzer*innen in der EU und der Schweiz geniessen. Über den reinen Datenzugriff hinaus manifestiert sich der staatliche Einfluss auch in der Funktionalität des Modells selbst: Eingebaute Zensurmechanismen für politisch sensible Themen können zu blockierten oder nur einseitig, regierungsfreundlichen Antworten führen, wodurch seine Neutralität untergraben wird.
KI-Modelle aus Europa und der Schweiz
Mistral AI: Das französische KI-Unternehmen hat sich mit schlanken, aber leistungsfähigen Modellen einen Namen gemacht. Ein entscheidender Punkt ist die duale Strategie: Modelle wie Mistral 7B und Mixtral 8x7B wurden unter der Apache 2.0-Lizenz veröffentlicht und sind damit echtes Open Source. Die neueren, leistungsstärkeren Modelle wie Mistral Large sind jedoch proprietär und nur über eine API zugänglich.
Swiss LLM: Das von der ETH Zürich und der EPFL entwickelte Sprachmodell (LLM) ist ein klares Bekenntnis zu echtem Open Source. Das im Rahmen der Swiss AI Initiative entwickelte Projekt garantiert vollständige Transparenz: Quellcode, Gewichte und – entscheidend – die reproduzierbaren Trainingsdaten sind allesamt öffentlich zugänglich. Dieses auf dem CSCS-Supercomputer «Alps» trainierte KI-Modell, das über 1000 Sprachen beherrscht, leistet damit einen wegweisenden Beitrag für eine offenere und nachvollziehbarere KI-Forschung.
Datensouveränität: Mehr als nur der Serverstandort
Sie haben im vorherigen Kapitel gelesen, dass der Begriff «Open Source» bei KI-Modellen offensichtlich dehnbar ist. Diese Erkenntnis wirft eine entscheidende Frage auf: Lässt sich Open-Source-KI nutzen, ohne unsere Daten und unsere digitale Unabhängigkeit zu gefährden? Die Antwort liegt im Erreichen von echter Datensouveränität.
Was bedeutet Datensouveränität im KI-Kontext wirklich?
Im Kern ist Datensouveränität die volle und uneingeschränkte Selbstbestimmung über die eigenen Daten. Im Kontext von KI bedeutet es, die vollständige Kontrolle und Hoheit darüber zu haben, welche Daten von KI-Systemen wie und für welche Zwecke genutzt werden dürfen. Was das in der Praxis bedeutet, lässt sich an einem konkreten Beispiel veranschaulichen.
Erreichen Sie Datensouveränität mit unserer KI-Architektur
Panter realisiert KI-Architekturen, die eine sichere und gezielte Abfrage interner Daten mit führenden KI-Modellen ermöglichen. Wir passen die Architektur exakt an Ihre Anforderungen an – unabhängig davon, ob Sie Google Gemini, den OpenAI GPT-Service, das Azure OpenAI-Angebot oder die Llama-Modelle von Meta AI über einen Schweizer Hosting-Provider nutzen möchten.
Der Praxistest: Wann sind meine Daten wirklich souverän?
Um die Kontrolle über die eigenen Daten zu behalten und die Anforderungen des Schweizer Datenschutzgesetzes (DSG) zu erfüllen sind folgende Punkte entscheidend:
Faktor 1: Der physische Serverstandort
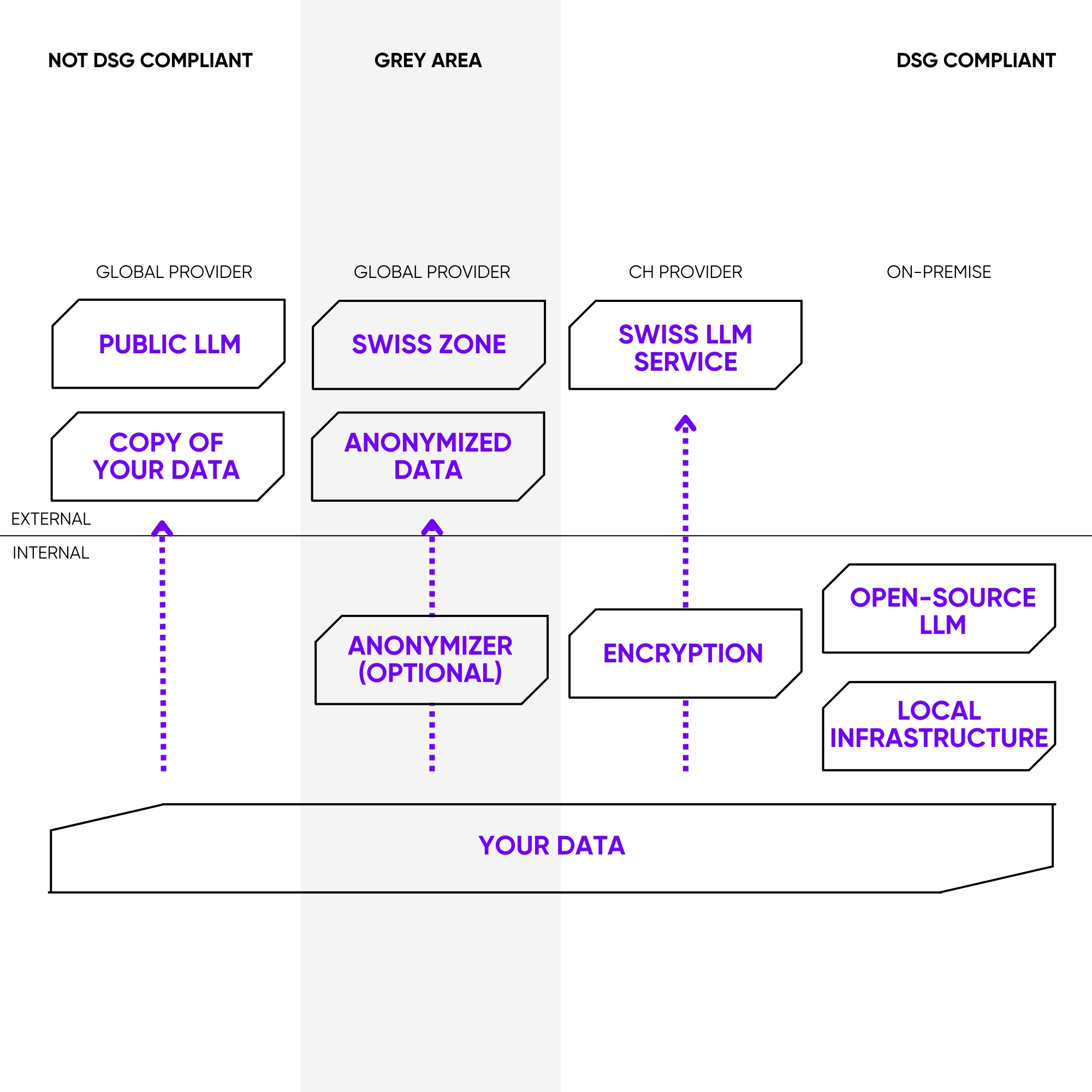
Es ist wichtig, dass der Server in der Schweiz steht. Dadurch unterliegen die gespeicherten und verarbeiteten Daten grundsätzlich dem schweizerischen Recht, insbesondere dem Bundesgesetz über den Datenschutz (DSG). Dies schützt die Daten vor dem direkten Zugriff ausländischer Behörden, wie er beispielsweise durch den US-amerikanischen CLOUD Act ermöglicht wird.
Faktor 2: Die Betriebsart. Hier liegt der Schlüssel
Ein weiterer zentraler Punkt ist, wie das KI-Modell genutzt wird.
Der Königsweg: Maximale Kontrolle durch Self-Hosting
Wenn ein Open-Source-Modell wie Llama auf einem eigenen Server (On-Premise) oder in einer privaten Cloud eines Schweizer Anbieters installiert und betrieben wird, ist die volle Kontrolle gegeben. Alle Daten, sowohl die Eingaben (Prompts) als auch die vom Modell generierten Ausgaben, bleiben innerhalb der eigenen Infrastruktur. Es findet kein Datenaustausch mit dem Hersteller des Modells (z.B. Meta) statt. Dies ist der sicherste Weg zur Datensouveränität.
Die Grauzone: Kontrollverlust durch API-Nutzung
Wenn Llama über die API eines Drittanbieters (möglicherweise sogar Meta selbst oder ein anderer grosser Cloud-Provider) genutzt wird, ist die Datensouveränität nicht mehr vollständig gewährleistet. Selbst wenn der Anbieter Server in der Schweiz nutzt, müssen dessen Datenschutzbestimmungen und Vertragsbedingungen genau geprüft werden. Es besteht das Risiko, dass Daten für andere Zwecke, wie zum Beispiel zur Verbesserung des KI-Modells des Anbieters, verwendet oder in andere Rechtsräume übertragen werden.
Fazit: Datensouveränität ist ein Bekenntnis zur Unabhängigkeit
Ein US-Modell auf einem Schweizer Server zu betreiben, ist oft nicht mehr als eine Scheinsicherheit. Es ist der Versuch, eine digitale Festung auf Schweizer Boden zu errichten, deren Bauplan aus den USA stammt. Das weckt falsche Sicherheit. Solange fremde Gesetze die Architekt*innen zwingen können, die Tore zu öffnen, bleibt die Kontrolle eine Illusion. Der wahre Weg zur Datensouveränität ist eine bewusste strategische Entscheidung und baut auf drei Grundpfeilern auf:
- Die richtige Technologie: Wählen Sie ein Modell, bei dem nicht nur die Gewichte, sondern der gesamte Bauplan offengelegt ist, also Quellcode, Trainingsdaten und Gewichte. Das von der ETH Zürich und der EPFL entwickelte Sprachmodell (LLM) zeigt, dass vollständige Transparenz möglich ist.
- Der richtige Standort: Betreiben Sie Ihre KI auf einer lokalen Infrastruktur, sei es auf eigenen Servern oder bei einem vertrauenswürdigen Schweizer Cloud-Anbieter. So entgehen Sie dem direkten Zugriff ausländischer Behörden.
- Das richtige Betriebsmodell: Vermeiden Sie den Kontrollverlust durch fremde APIs. Nur durch Self-Hosting behalten Sie die uneingeschränkte Kontrolle darüber, welche Daten wie und wofür verarbeitet werden.
Die Wahl des KI-Modells und dessen Betriebsart ist am Ende mehr als eine technische Frage. Es ist ein Bekenntnis zu Transparenz, Kontrolle und digitaler Unabhängigkeit. Wenn Sie auf echtes Open Source und konsequentes Self-Hosting setzen, nutzen Sie nicht nur KI. Sie gestalten die Spielregeln selbst und sichern sich so das wertvollste Gut im digitalen Zeitalter: die Datensouveränität.
