Sprecher: Lewis Tunstall
Location: Colab & Café Auer & Co.
Möglichkeiten und Grenzen von (Open-Source) ChatGPT
Lewis hob die beeindruckenden Fähigkeiten und den Datenabgleich von ChatGPT hervor. Tatsächlich gibt es aber auch einige Einschränkungen, z. B. wenn der Datenabgleich mit gültigen Anwendungsfällen kollidiert (siehe unten). Erwähnt wurden auch die Unvereinbarkeit mit Datenschutzanforderungen und die unvorhersehbare Performance bei Aktualisierungen.
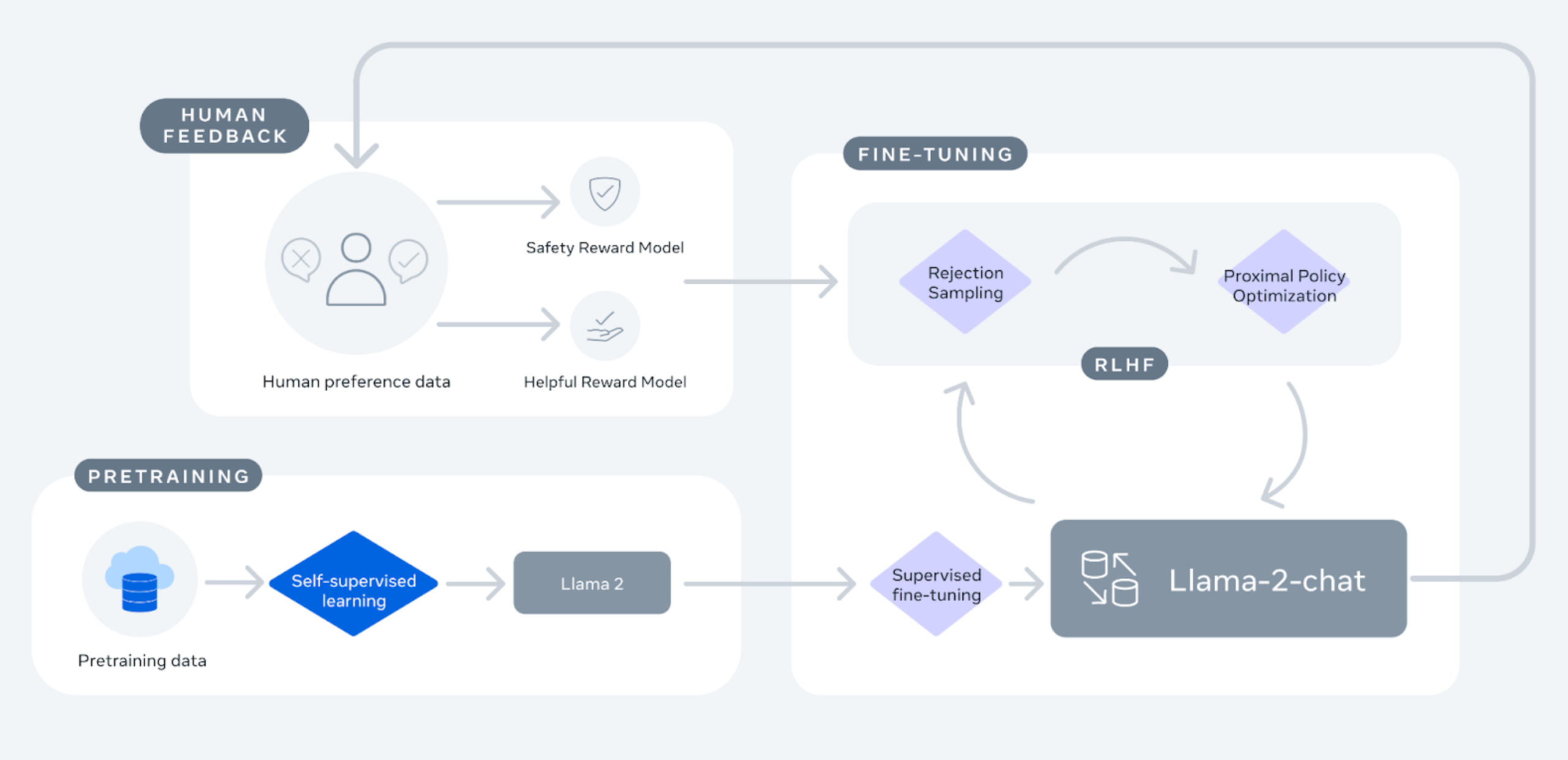
Umkehrung der ChatGPT-Rezeptur
Lewis erörterte auch ein mögliches Verfahren zum Reverse Engineering von ChatGPT und wies darauf hin, dass das eigentliche „Rezept“ für ChatGPT nicht öffentlich ist. Allerdings wurde Llama 2 als wertvolle Blaupause für das Verständnis der zugrunde liegenden Mechanismen verwendet. Der Prozess beinhaltete, mit einem guten Basis-LLM zu beginnen, unter Verwendung von Metas freigegebenem Llama (Februar 2023), und dann durch überwachte Feinabstimmung fortzufahren, beispielhaft durch Stanfords Feinabstimmung von Alpaca und die anschliessende Erstellung von Vicuña 13B durch LMSYS. Es wurde betont, wie wichtig qualitativ hochwertige Vergleichsdaten sind, die entweder aus dem Internet oder aus bezahlten bzw. von der Crowd bereitgestellten Modellrankings stammen. Lewis erläuterte auch die drei Hauptschritte des Reinforcement Learnings für die Ausrichtung des LLM: Einführung, Bewertung und Optimierung.
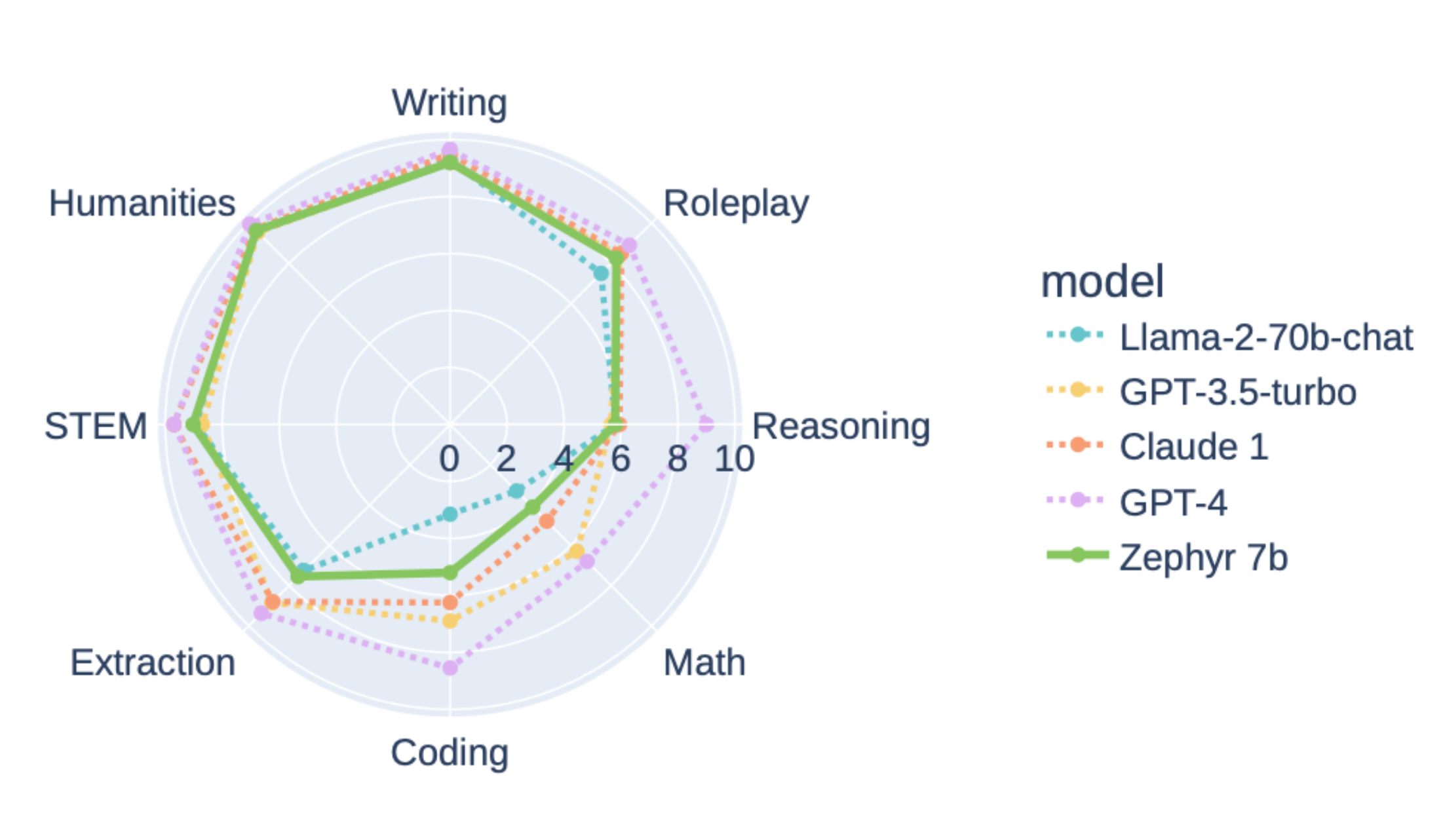
Aktuelle Defizite in der Chatbot-Entwicklung
Lewis schloss mit einem Hinweis auf die aktuellen Herausforderungen und Lücken in diesem Bereich. Die Bewertung der Fähigkeiten von Chatbots wurde als eine schwierige Aufgabe bezeichnet, und er wies auch auf die Kosten hin, die mit der Erhebung menschlicher Präferenzdaten verbunden sind. Abschliessend ging er auf spezifische Probleme mit ChatGPT ein, darunter Einschränkungen bei der Codierung, dem logischen Denken und den mathematischen Fähigkeiten.