
Imagine buying an organic product only to find that the seeds have been genetically modified and the soil contaminated with unknown substances.
The situation is similar with many AI models declared as “open”. “Open source AI” promises companies, developers and visionaries more control in order to escape dependence on big tech giants. But there are pitfalls behind this promise: unclear licenses, non-transparent training data that harbour incalculable risks such as “memorization”, and even geopolitical interests that are woven right into the core of the models.
In this blog post, we explain what “true open source” really means, take a critical look at the most prominent AI models from the USA, China and Europe and show why simply operating on a Swiss server can be deceptively secure.
What is open source AI?
Open source AI refers to artificial intelligence whose key core components are publicly accessible, viewable, modifiable and freely reusable. These three components are:
- The source code, i.e. the actual architecture of the model.
- The training data that taught the model what it knows.
- The model weights that form the “brain” of the model and define its capabilities.
This is precisely the difference between models with only open weights (open-weight) and truly open-source models (true open-source). While Open-Weight often only releases the final model weights, True Open-Source discloses all three components. Only in this way is it possible to fully analyze, adapt and reproduce the training.
This concept of complete transparency, i.e. true open source, breaks open the “black box” of many commercial AI systems and, according to the official definition of the Open Source Initiative, is based on four central freedoms:
- Use: The freedom to use the AI system for any purpose.
- Study: The freedom to investigate exactly how the system works, which requires access to all components.
- Modification (Modify): The freedom to change and adapt the system for your own purposes.
- Share: The freedom to share the original or modified system with others to drive collective development.
Not all that glitters is open source
The term “open” has become a marketing tool in the global race for AI supremacy. But there are often considerable differences behind the façade. Whether a model is truly trustworthy depends not only on its performance, but above all on its transparency, its license and the legal framework in which it operates. The differences become clear when you look at the individual players operating worldwide.
AI models from the USA
Llama: The Llama models from Meta AI are perhaps the strongest competitors to the large closed systems. Meta pursues an “open weight” strategy in which the model weights are made widely available. Although the models are not open source in the strict sense, their availability drives innovation and supports Meta in integrating AI into its own products. However, the use of Llama is viewed critically, especially in the EU/CH. The main reason for this is the lack of transparency regarding the training data. This can lead to memorization. This means that an AI model is able to reproduce certain phrases or passages from its training data verbatim. This is particularly problematic with sensitive or private information.
gpt-oss: In August 2025, OpenAI released gpt-oss, two state-of-the-art open weight language models. Due to its open licensing and free use, the model is much more accessible to developers and researchers than previous OpenAI models. However, as with the Llama models, it is not completely transparent in the sense of open source.
AI models from China
DeepSeek R1: Although this AI model from China impresses with its impressive efficiency and low operating costs, its very origin is the source of major concerns. The Chinese legal system creates a direct conflict of interest here. Under Chinese law, Chinese authorities have extensive access to stored data. This also applies if the data is stored on servers outside of China, as long as it concerns the personal data of Chinese citizens or the data processing is linked to the offering of products and services to people in China. This contradicts the significantly higher level of protection enjoyed by users in the EU and Switzerland. In addition to pure data access, the state’s influence also manifests itself in the functionality of the model itself: Built-in censorship mechanisms for politically sensitive topics can lead to blocked or only one-sided, pro-government responses, undermining its neutrality.
AI models from Europe and Switzerland
Mistral AI: The French AI company has made a name for itself with lean but powerful models. A crucial point is the dual strategy: models such as Mistral 7B and Mixtral 8x7B were published under the Apache 2.0 license and are therefore genuine open source. However, the newer, more powerful models such as Mistral Large are proprietary and only accessible via an API.
Swiss LLM: The language model (LLM) developed by ETH Zurich and EPFL is a clear commitment to genuine open source. The language model developed as part of the Swiss AI Initiative initiative guarantees complete transparency: source code, weights and – crucially – the reproducible training data are all publicly accessible. This AI model, trained on the CSCS supercomputer “Alps” and capable of over 1000 languages, thus makes a pioneering contribution to more open and comprehensible AI research.
Data sovereignty: more than just the server location
You read in the previous chapter that the term “open source” is obviously open to interpretation when it comes to AI models. This realization raises a crucial question: Can open source AI be used without jeopardizing our data and our digital independence? The answer lies in achieving true data sovereignty.
What does data sovereignty really mean in the context of AI?
At its core, data sovereignty is full and unrestricted self-determination over one’s own data. In the context of AI, it means having complete control and sovereignty over which data may be used by AI systems, how and for what purposes. What this means in practice can be illustrated using a specific example.
Achieve data sovereignty with our AI architecture
Panter implements AI architectures that enable secure and targeted querying of internal data with leading AI models. We customize the architecture exactly to your requirements – regardless of whether you want to use Google Gemini, the OpenAI GPT service, the Azure OpenAI offering or Meta AI’s Llama models via a Swiss hosting provider.
The practical test: When is my data really sovereign?
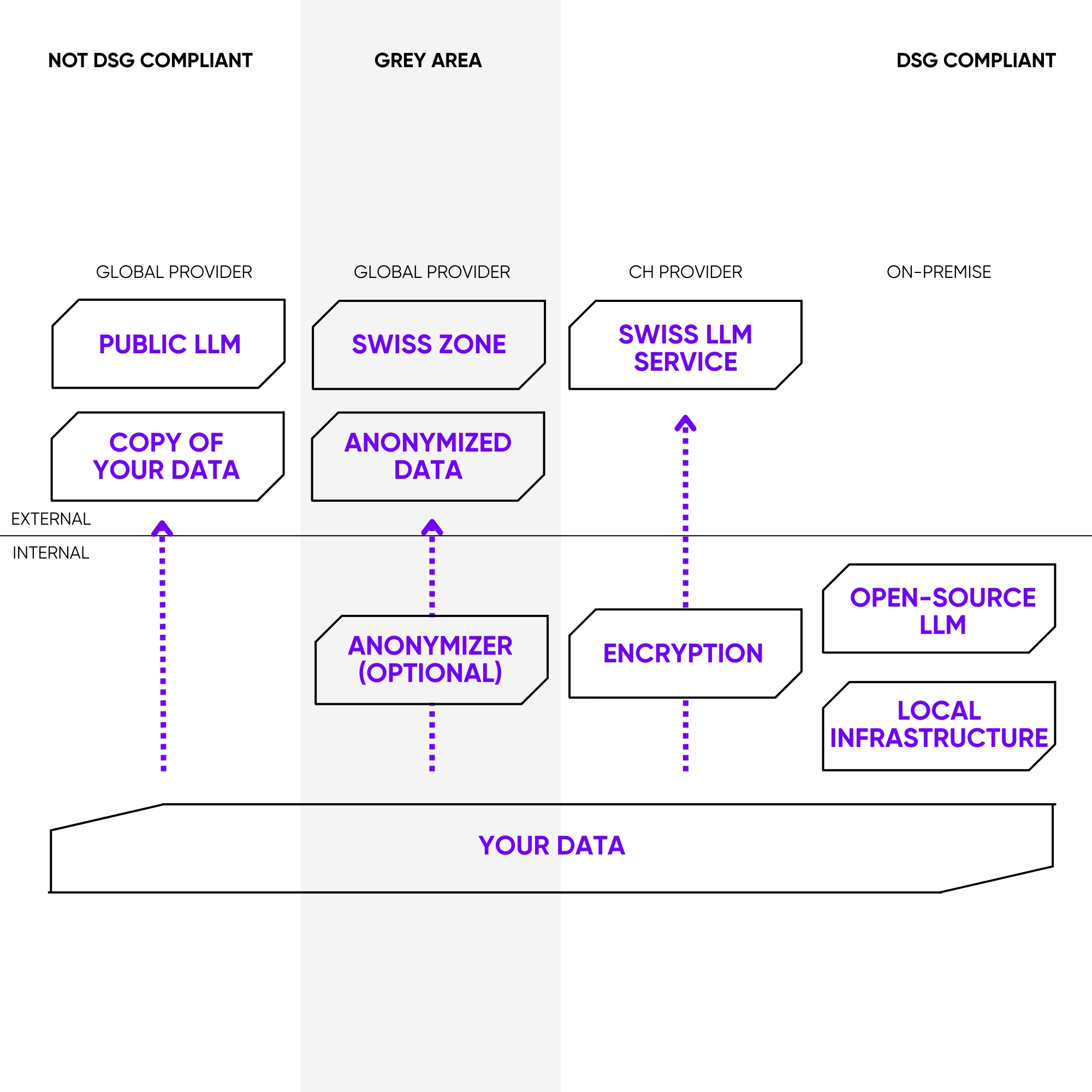
In order to retain control over your own data and meet the requirements of the Swiss Data Protection Act (DPA), the following points are crucial:
Factor 1: The physical server location
It is important that the server is located in Switzerland. This means that the stored and processed data is generally subject to Swiss law, in particular the Federal Act on Data Protection (FADP). This protects the data from direct access by foreign authorities, such as under the US CLOUD Act is made possible.
Factor 2: The operating mode. This is the key
Another key point is how the AI model is used.
The ideal solution: maximum control through self-hosting
If an open source model such as Llama is installed and operated on your own server (on-premise) or in a private cloud from a Swiss provider, you have full control. All data, both the inputs (prompts) and the outputs generated by the model, remain within the company’s own infrastructure. There is no data exchange with the manufacturer of the model (e.g. Meta). This is the safest way to achieve data sovereignty.
The gray area: loss of control through API usage
If Llama is used via the API of a third-party provider (possibly even Meta itself or another large cloud provider), data sovereignty is no longer fully guaranteed. Even if the provider uses servers in Switzerland, its data protection provisions and contractual conditions must be checked carefully. There is a risk that data will be used for other purposes, such as improving the provider’s AI model, or transferred to other jurisdictions.
Conclusion: Data sovereignty is a commitment to independence
Operating a US model on a Swiss server is often nothing more than a sham security measure. It is an attempt to build a digital fortress on foreign soil, the blueprint for which originates in the USA. This creates a false sense of security. As long as foreign laws can force the architects to open the gates, control will remain an illusion. The true path to data sovereignty is a conscious strategic decision and is based on three pillars:
- The right technology: Choose a model in which not only the weights but also the entire blueprint is disclosed, i.e. source code, training data and weights. The language model (LLM) developed by ETH Zurich and EPFL shows that complete transparency is possible.
- The right location: Operate your AI on a local infrastructure, be it on your own servers or with a trustworthy Swiss cloud provider. This way you avoid direct access by foreign authorities.
- The right operating model: Avoid losing control through third-party APIs. Only through self-hosting do you retain full control over what data is processed, how and for what purpose.
The choice of AI model and its operating mode is ultimately more than just a technical question. It is a commitment to transparency, control and digital independence. If you opt for genuine open source and consistent self-hosting, you are not just using AI. You shape the rules of the game yourself and secure the most valuable asset in the digital age: data sovereignty.
